Python爬虫实战——百度贴吧一键签到
字数统计:571 阅读时长 ≈ 2分钟前言
百度贴吧官方的一键签到有以下缺点:
- 只能给前几个贴吧签到
- 需要手动点击“一键签到”,无法实现每日自动签到
目标
- 目标网址:https://tieba.baidu.com/index.html
- 程序目的:批量签到
分析
- 通过python爬虫模拟登录百度贴吧(cookies)
- 获取需要签到的贴吧 名称/ID
- 模拟签到(注意两次签到之间的间隔)
过程
1. 找到POST方式与Form Data
- 首先打开一个贴吧签到页面,在签到前按F12,选择Network。
- 由于要的是request请求,所以筛选XHR。点击签到:
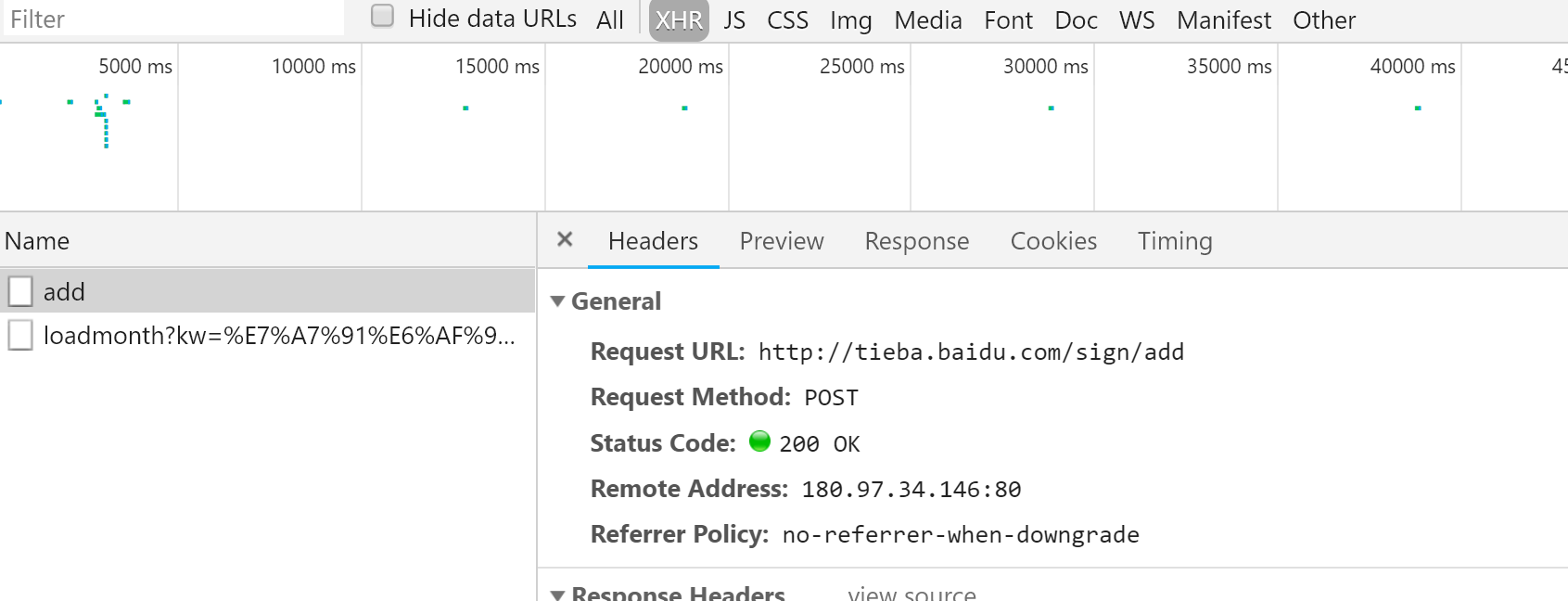

- 得到一个add请求,明显是我们需要的。
查看add请求,得到
Request URLhttp://tieba.baidu.com/sign/add
Request MethodPOST
Form Data
ie:utf-8
kw:贴吧名称
tbs:- tbs可以复用,即每个贴吧可以共用,现在只需要得到所有贴吧的名字,然后做好对应的data,post发送即可
2. 获取所有关注的贴吧名称
- 从贴吧里找到我的贴吧界面
用F12打开后,点击Network,按一下F5重新加载一下网页,得到一堆结果,我们要的是request请求,筛选选择XHR后就简单多了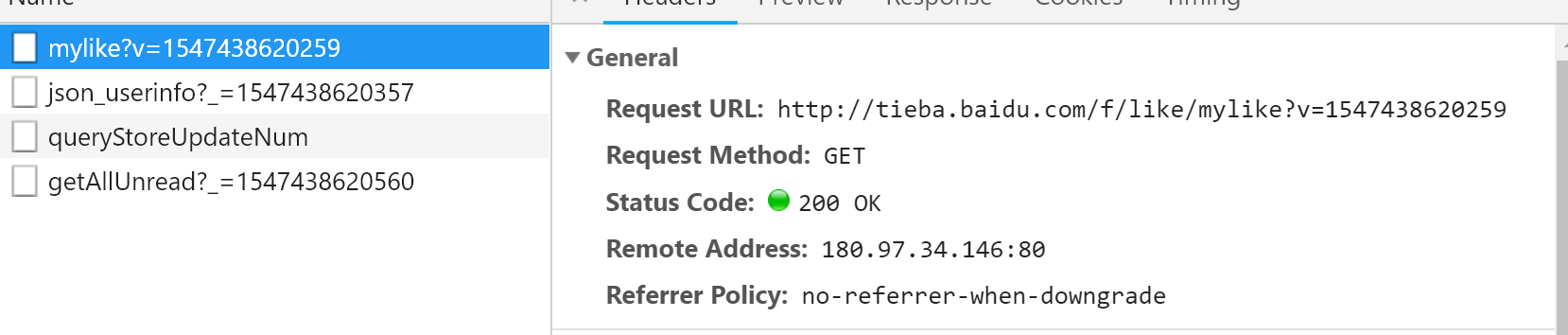
发现有个mylike请求,双击点开发现正是关注贴吧的列表
得到了请求的url为 http://tieba.baidu.com/f/like/mylike?v=1547438620259
请求方法为 GET
下面也有请求头部的信息,里面包含了cookie,不管那么多,直接全部复制头部信息,进入python代码里,处理只需加一下单引号和逗号就能构造好带有自己cookie的头部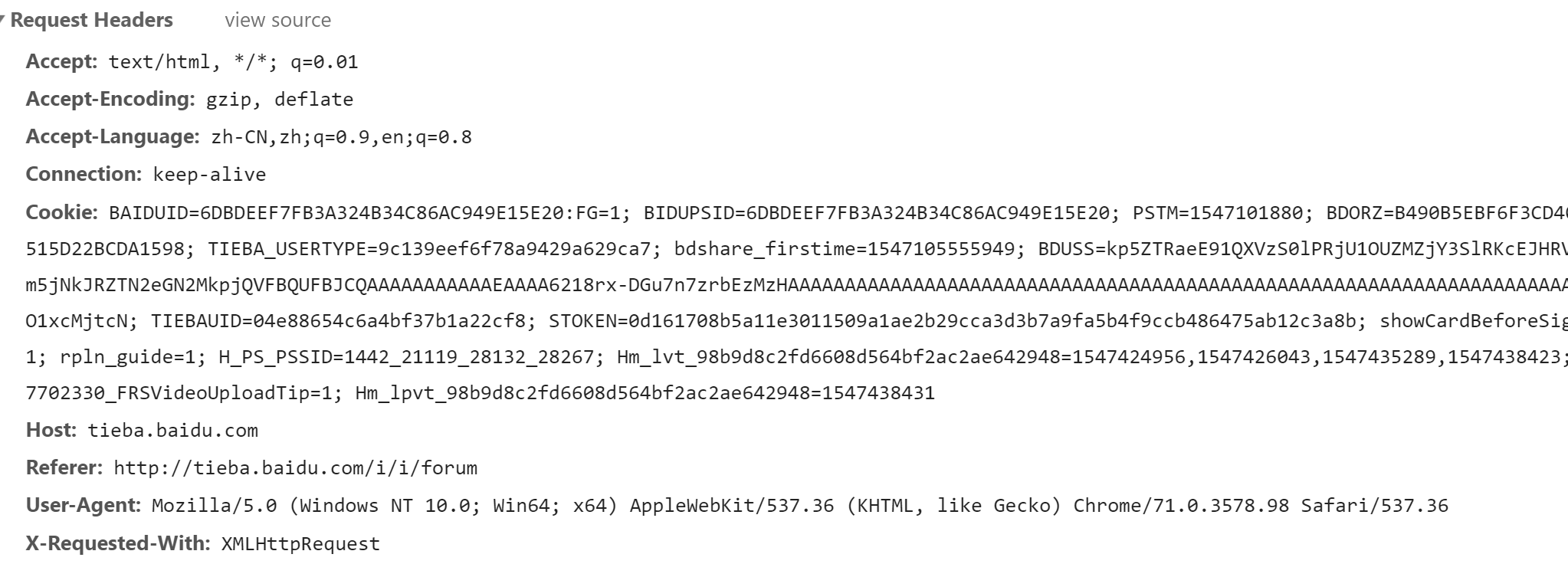
代码里的头部构造,复制过来后修改的地方非常少,看着很花里胡哨,其实很省心
3. 登陆贴吧
- 在贴吧首页右键-查看网页源代码
- 用ctrl+f搜索其中一个关注的贴吧名,找到如下数据结构

- 其中forum_name应该就是贴吧名,观察可知正则表达式比较好匹配,匹配得到forum_name后在重新编/解码就可以得到正确的贴吧名
- 这里请求贴吧列表时有个重定向,用urllib中的opener不行,这里用requests的Session来处理,即可重定向时照样保存cookie信息
# 通过cookies获取网页源码
target_url = 'http://tieba.baidu.com'
s = requests.Session()
html = s.get(target_url, headers=headers)
html = html.content.decode('utf-8')
# 用正则表达式获取源码中的贴吧名
name_list_raw = re.findall(r'"forum_id":(.*?),"forum_name":"(.*?)"', html)
#重新编码解码,并获取正确的贴吧名
for name in name_list_raw:
name_list.append(name[1].encode('latin-1').decode("unicode_escape"))4. 通过for循环签到所有关注的吧
# 开始签到
for name in name_list:
data = {
'ie': 'utf-8',
'kw': name,
'tbs': tbs
}
try:
r = requests.post(sign_url, data=data, headers=headers)
except urllib.error.HTTPError as e:
print(e.reason)
本文由simyng创作,
采用知识共享署名4.0 国际许可协议进行许可,转载前请务必署名
文章最后更新时间为:February 4th , 2020 at 04:51 pm