Pytorch使用GPU加速计算
字数统计:653 阅读时长 ≈ 2分钟前言
深度学习中一类成功应用的技术叫做卷积神经网络CNN,这种网络数学上就是许多卷积运算和矩阵运算的组合,而卷积运算通过一定的数学手段也可以通过矩阵运算完成。这些操作和GPU本来能做的那些图形点的矩阵运算是一样的。因此深度学习就可以非常恰当地用GPU进行加速了。
查看电脑是否支持GPU计算
默认情况下,Pytorch将数据保存在内存,而不是显存。
可以通过以下代码查看显卡信息(Linux环境下或cmd):
nvidia-smi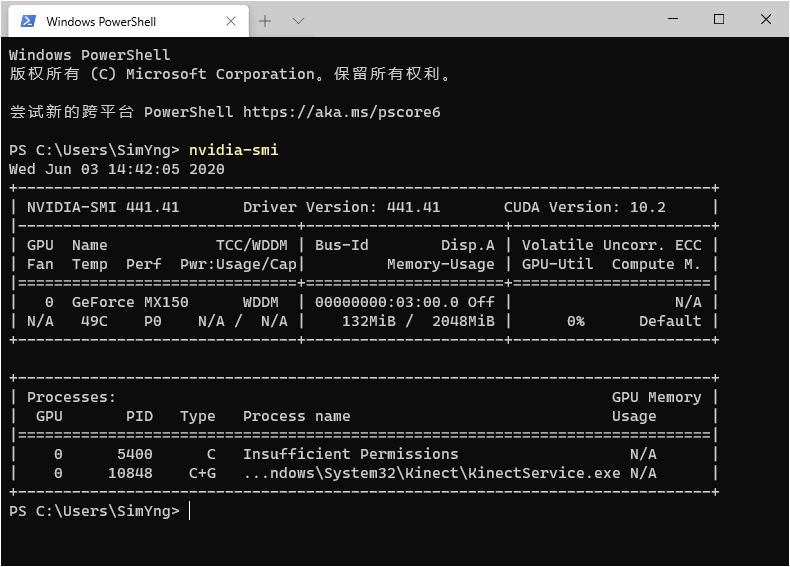
查看gpu是否可用:
torch.cuda.is_available()查看gpu数量:
torch.cuda.device_count()查看当前gpu号:
torch.cuda.current_device()查看设备名:
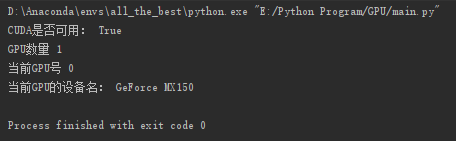
torch.cuda.get_device_name(device_id)完整测试代码:
import torch
def main():
print("CUDA是否可用:", torch.cuda.is_available())
print("GPU数量", torch.cuda.device_count())
print("当前GPU号", torch.cuda.current_device())
print("当前GPU的设备名:",torch.cuda.get_device_name(torch.cuda.current_device()))
if __name__ == '__main__':
main()
使用GPU进行加速训练
把tensor复制到显存
使用.cuda()可以将CPU上的Tensor转换(复制)到GPU上。
如果有多块GPU,我们用.cuda(i)来表示第 i 块GPU及相应的显存(i从0开始)且cuda(0)和cuda()等价。
x=x.cuda()直接在显存上存储数据
device = torch.device('cuda')
x = torch.tensor([1, 2, 3], device=device)或者
x = torch.tensor([1,2,3]).to(device)如果对在GPU上的数据进行运算,那么结果还是存放在GPU上
y = x**2
y输出:
tensor([1, 4, 9], device='cuda:0')需要注意的是,存储在不同位置中的数据是不可以直接进行计算的。即存放在CPU上的数据不可以直接与存放在GPU上的数据进行运算,位于不同GPU上的数据也是不能直接进行计算的。
z = y + x.cpu()RuntimeError: expected device cuda:0 and dtype Long but got device cpu and dtype Long具体使用示例
判断是否支持GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 启用GPU
model = model.to(device)完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.autograd import Variable
# 定义全局变量
lr = 0.01 #学习率
momentum = 0.5
log_interval = 10 #跑多少次batch进行一次日志记录
epochs = 10
batch_size = 64
test_batch_size = 1000
train_loader = torch.utils.data.DataLoader( # 加载训练数据
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 数据集给出的均值和标准差系数.数据集提供方给出的
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader( # 加载训练数据
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 数据集给出的均值和标准差系数.数据集提供方给出的
])),
batch_size=test_batch_size, shuffle=True)
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 6, 5, 1, 2), # padding=2保证输入输出尺寸相同
nn.ReLU(), # input_size=(6*28*28)
nn.MaxPool2d(kernel_size=2, stride=2), # output_size=(6*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(), # input_size=(16*10*10)
nn.MaxPool2d(2, 2) # output_size=(16*5*5)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
# 定义前向传播过程,输入为x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x # F.softmax(x, dim=1)
model = LeNet() # 实例化一个网络对象
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 启用GPU
model = model.to(device)
def train(n_epochs,max_acc=0.995): # 定义每个epoch的训练细节
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum) # 初始化优化器
model.train() # 设置为trainning模式
acc = 0
for epoch in range(1, n_epochs + 1): # 以epoch为单位进行循环
train_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data = data.to(device)
target = target.to(device)
data, target = Variable(data), Variable(target) # 把数据转换成Variable
optimizer.zero_grad() # 优化器梯度初始化为零
output = model(data) # 把数据输入网络并得到输出,即进行前向传播
loss = F.cross_entropy(output, target) # 交叉熵损失函数
loss.backward() # 反向传播梯度
optimizer.step() # 结束一次前传+反传之后,更新参数
train_loss = loss.item()
test_loss, acc = test()
print("dataset:Minist | methods:CNN | epoch: {0:04d} | loss: {1:.6f} | acc: {2:.1f}%".format(
epoch, train_loss, acc * 100))
if acc > max_acc: return acc
return acc
def test():
model.eval() # 设置为test模式
test_loss = 0 # 初始化测试损失值为0
correct = 0
total = 0
with torch.no_grad(): # 训练集中不需要反向传播
for images,labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
test_loss += F.cross_entropy(outputs, labels, size_average=False).item() # sum up batch loss 把所有loss值进行累加
correct += (predicted == labels).sum().item()
return test_loss / total, correct / total
if __name__ == '__main__':
minist_cnn_acc = round(train(n_epochs=50, max_acc=0.995), 4)
print("模拟测试结果为:", minist_cnn_acc)
torch.save(model, 'model.pth') # 保存模型
本文由simyng创作,
采用知识共享署名4.0 国际许可协议进行许可,转载前请务必署名
文章最后更新时间为:June 3rd , 2020 at 03:16 pm